
Following on from this post, for anyone who's interested in getting ActivityPub integrated on their static site, this is what I've needed to setup/build (some of this may indeed be redundant, but it 'evolved' over time, so easier just to leave alone than fix).
\nSome not-hugely-relevant background: I have a custom-built site generator, written in Python, pushing files via git to a Gitea instance and pulled via a cronjob to a dir where they're served by Apache2 (with Cloudflare in front). Everything is static, apart from (now) the inbox required for ActivityPub to work.
\nIn terms of static ActivityPub content, there are a bunch of JSON files required (I'll probably butcher the descriptions of these, but whatever ¯\\_(ツ)_/¯ ):
\nAlong with these, I've got another JSON \"profile\"...
\njasonrbriggs@jasonrbriggs.com.json
\n...which is used for webfinger (more on that shortly).
\nMy rewrite rules for the first set of files look like this:
\nRewriteRule ^actor$ /@me/actor [R=301,L]\nRewriteRule ^@me$ /@me/actor [R=301,L]\nRewriteRule ^@me/$ /@me/actor [R=301,L]\nRewriteRule ^@jasonrbriggs$ /@me/actor [R=301,L]\nRewriteRule ^@jasonrbriggs/$ /@me/actor [R=301,L]\nRewriteRule ^followers$ /@me/followers\n\n# force content type\nRewriteRule @me/actor - [env=headerjs:1]\nHeader set Content-type application/activity+json env=headerjs\nRewriteRule @me/outbox - [env=headerjs:1]\nHeader set Content-type application/activity+json env=headerjsFor the aforementioned webfinger, there's one more rewrite rule:
\nRewriteCond %{QUERY_STRING} (?:^|&)(resource=acct:jasonrbriggs@jasonrbriggs.com$) [NC]\nRewriteRule ^\\.well-known/webfinger /profile/jasonrbriggs@jasonrbriggs.com.json [L]That takes care of the discovery aspects of the process (the self link in the webfinger profile points to the actor).
I do have a couple more rewrite rules for the @me directory which redirect browser requests (basically for text/html) to my local archive of \"micro posts\":
RewriteCond %{HTTP:Accept} text/html [NC]\nRewriteRule ^@me$ /micro/ [R=301,L]\nRewriteCond %{HTTP:Accept} text/html [NC]\nRewriteRule ^@me/$ /micro/ [R=301,L](Why \"@me\"? Because I was originally planning @me@jasonrbriggs.com as my ActivityPub address, before changing my mind and going with @jasonrbriggs@jasonrbriggs.com, and I never got around to fixing).
\nAs mentioned, the only part of my site which is (unfortunately) not static is the ActivityPub inbox, because you need to be able to accept POST follow requests and other notification activities from the fediverse. For the inbox, I've built a very simple Flask/WSGI app to do the very minimum (just file-based, no database, hopefully as minimal impact as possible).
\nI've also built a local (ie. not web-based) command-line Python app which can be used to send an Accept activity to a follow request (it should also add the follower to the follower's list, but I haven't gotten around to that yet); additionally, it retrieves all new posted content from the outbox and delivers that content to each follower's inbox. I'm not posting the code to github - at least not yet - because it's a bit of a mess. If anyone's enthusiastic to use unsupported Python code for this, feel free to get in contact.
\nThe final piece of the puzzle is a separate Mastodon account (I've had one on mastodon.social for a while) where you send yourself a follow request, and then accept it - this not only tests that follow/accept works, but then you can see that your posts are correctly appearing at least somewhere in the fediverse.
\nSo the nice part of all this, is that a micro post on my site is also added to the outbox, and shortly after it now appears on Mastodon (viewable here for example).
", "date_published": "2023-05-08T09:44:15+00:00" }, { "id": "https://jasonrbriggs.com/journal/2023/05/03/python-humble-bundle.html", "title": "Python Humble Bundle", "url": "https://jasonrbriggs.com/journal/2023/05/03/python-humble-bundle.html", "content_text": "The second edition of Python for Kids is a part of the [Python Humble Bundle](https://www.humblebundle.com/books/python-no-starch-books) - along with a bunch of other [No Starch](https://nostarch.com) Python books. Pay what you want... but it's for charity (supporting the Python Software Foundation), so why not pay more than you want? ツ\n", "content_html": "The second edition of Python for Kids is a part of the Python Humble Bundle - along with a bunch of other No Starch Python books. Pay what you want... but it's for charity (supporting the Python Software Foundation), so why not pay more than you want? ツ
", "date_published": "2023-05-03T20:17:54+00:00" }, { "id": "https://jasonrbriggs.com/journal/2023/04/30/mastodon-and-http-sig.html", "title": "Mastodon and http sig", "url": "https://jasonrbriggs.com/journal/2023/04/30/mastodon-and-http-sig.html", "content_text": "I've been trying to integrate [ActivityPub](https://www.w3.org/TR/activitypub/) (basically [Mastodon](https://joinmastodon.org/)) into my static site with varying levels of success. The most difficult part is the [inbox](https://www.w3.org/TR/activitypub/#inbox) which is obviously **not** static - there are 3rd party services to help, like [fed.brid.gy](https://fed.brid.gy/), but I had limited success with that unfortuately, so in the end I've rolled my own basic inbox. The next major hurdle was responding to activities (like [follow](https://www.w3.org/TR/activitypub/#follow-activity-outbox) requests for example) -- it is not at all obvious how to sign the request so Mastodon will accept the response. Finally got it working (with the help of a lot of searching and, funnily enough, guidance from ChatGPT - which wasn't perfect, but definitely helped).\n\nThe most important part (and the bit that I really struggled to find examples for) is the signature string, which needs to be formatted like this:\n\n```python\nsignature_string = f'''(request-target): post {url}\nhost: {headers['Host']}\ndate: {now.strftime('%a, %d %b %Y %H:%M:%S GMT')}\ndigest: {headers['Digest']}'''\n```\n\nWhere the digest is the base64-encoded SHA-256 digest of the encoded content:\n\n```python\nhash_algorithm = hashlib.sha256()\nhash_algorithm.update(json_data.encode())\nbody_hash = base64.b64encode(hash_algorithm.digest()).decode()\nheaders['Digest'] = f'SHA-256={body_hash}'\n```\n\nHere's the full example code (note you need a public key on your [actor](https://www.w3.org/TR/activitypub/#actor-objects) profile, with the matching private key pem file stored locally in .ssh/private.pem). The id of the Accept activity response is simply a pre-generated UUID (at some point, I'll put some more effort into storing the stuff locally in a sqlite db, I guess).\n\n```python\nfrom datetime import datetime\nimport time\nimport hashlib\nimport json\nimport base64\nimport sys\n\nimport requests\nfrom Crypto.Signature import pkcs1_15\nfrom Crypto.Hash import SHA256\nfrom Crypto.PublicKey import RSA\n\nnow = datetime.utcnow()\n\nbase_url = 'https://mastodon.social' \nurl = '/users/jasonrbriggs/inbox'\n\ndata = {\n \"@context\": \"https://www.w3.org/ns/activitystreams\",\n \"type\": \"Accept\",\n \"actor\": \"https://jasonrbriggs.com/@me/actor\",\n \"object\": {\n \"type\": \"Follow\",\n \"actor\": \"https://mastodon.social/users/jasonrbriggs\",\n \"object\": \"https://jasonrbriggs.com/@me/actor\"\n },\n \"id\": \"https://jasonrbriggs.com/response/e958f9a9-4330-4df5-8ffa-4a4a1657c0db\",\n \"summary\": \"Accepted follow request\",\n \"published\": \"2023-04-14T22:12:00Z\"\n}\njson_data = json.dumps(data)\n\nkey_id = 'https://jasonrbriggs.com/@me/actor#main-key'\ntimestamp = now.strftime('%Y-%m-%dT%H:%M:%SZ')\n\nheaders = {\n 'Host': 'mastodon.social',\n 'Date': now.strftime('%a, %d %b %Y %H:%M:%S GMT'),\n 'Accept': 'application/json',\n 'Content-Type': 'application/activity+json'\n}\n\nhash_algorithm = hashlib.sha256()\nhash_algorithm.update(json_data.encode())\nbody_hash = base64.b64encode(hash_algorithm.digest()).decode()\nheaders['Digest'] = f'SHA-256={body_hash}'\n\nprivate_key_data = open('.ssh/private.pem', 'rb').read()\nprivate_key = RSA.import_key(private_key_data)\n\nsignature_template = 'keyId=\"{0}\",algorithm=\"rsa-sha256\",headers=\"(request-target) host date digest\",signature=\"{1}\"'\nsignature_headers = 'host date digest'\nsignature_string = f'''(request-target): post {url}\nhost: {headers['Host']}\ndate: {now.strftime('%a, %d %b %Y %H:%M:%S GMT')}\ndigest: {headers['Digest']}'''\n\nsignature = pkcs1_15.new(private_key).sign(SHA256.new(signature_string.encode()))\nsignature_b64 = base64.b64encode(signature).decode()\nhttp_signature = signature_template.format(key_id, signature_b64)\nheaders['Signature'] = http_signature\n\nresponse = requests.post(base_url + url, data=json_data, headers=headers)\nprint(response.status_code, response.content)\n```\n\n(Note: this is an Accept response to a Follow request from my [mastodon.social account](https://mastodon.social/@jasonrbriggs) to my static site - searchable via mastodon.social using [this link](https://mastodon.social/@jasonrbriggs@jasonrbriggs.com)) ", "content_html": "I've been trying to integrate ActivityPub (basically Mastodon) into my static site with varying levels of success. The most difficult part is the inbox which is obviously not static - there are 3rd party services to help, like fed.brid.gy, but I had limited success with that unfortuately, so in the end I've rolled my own basic inbox. The next major hurdle was responding to activities (like follow requests for example) -- it is not at all obvious how to sign the request so Mastodon will accept the response. Finally got it working (with the help of a lot of searching and, funnily enough, guidance from ChatGPT - which wasn't perfect, but definitely helped).
\nThe most important part (and the bit that I really struggled to find examples for) is the signature string, which needs to be formatted like this:
\nsignature_string = f'''(request-target): post {url}\nhost: {headers['Host']}\ndate: {now.strftime('%a, %d %b %Y %H:%M:%S GMT')}\ndigest: {headers['Digest']}'''Where the digest is the base64-encoded SHA-256 digest of the encoded content:
\nhash_algorithm = hashlib.sha256()\nhash_algorithm.update(json_data.encode())\nbody_hash = base64.b64encode(hash_algorithm.digest()).decode()\nheaders['Digest'] = f'SHA-256={body_hash}'Here's the full example code (note you need a public key on your actor profile, with the matching private key pem file stored locally in .ssh/private.pem). The id of the Accept activity response is simply a pre-generated UUID (at some point, I'll put some more effort into storing the stuff locally in a sqlite db, I guess).
\nfrom datetime import datetime\nimport time\nimport hashlib\nimport json\nimport base64\nimport sys\n\nimport requests\nfrom Crypto.Signature import pkcs1_15\nfrom Crypto.Hash import SHA256\nfrom Crypto.PublicKey import RSA\n\nnow = datetime.utcnow()\n\nbase_url = 'https://mastodon.social' \nurl = '/users/jasonrbriggs/inbox'\n\ndata = {\n \"@context\": \"https://www.w3.org/ns/activitystreams\",\n \"type\": \"Accept\",\n \"actor\": \"https://jasonrbriggs.com/@me/actor\",\n \"object\": {\n \"type\": \"Follow\",\n \"actor\": \"https://mastodon.social/users/jasonrbriggs\",\n \"object\": \"https://jasonrbriggs.com/@me/actor\"\n },\n \"id\": \"https://jasonrbriggs.com/response/e958f9a9-4330-4df5-8ffa-4a4a1657c0db\",\n \"summary\": \"Accepted follow request\",\n \"published\": \"2023-04-14T22:12:00Z\"\n}\njson_data = json.dumps(data)\n\nkey_id = 'https://jasonrbriggs.com/@me/actor#main-key'\ntimestamp = now.strftime('%Y-%m-%dT%H:%M:%SZ')\n\nheaders = {\n 'Host': 'mastodon.social',\n 'Date': now.strftime('%a, %d %b %Y %H:%M:%S GMT'),\n 'Accept': 'application/json',\n 'Content-Type': 'application/activity+json'\n}\n\nhash_algorithm = hashlib.sha256()\nhash_algorithm.update(json_data.encode())\nbody_hash = base64.b64encode(hash_algorithm.digest()).decode()\nheaders['Digest'] = f'SHA-256={body_hash}'\n\nprivate_key_data = open('.ssh/private.pem', 'rb').read()\nprivate_key = RSA.import_key(private_key_data)\n\nsignature_template = 'keyId=\"{0}\",algorithm=\"rsa-sha256\",headers=\"(request-target) host date digest\",signature=\"{1}\"'\nsignature_headers = 'host date digest'\nsignature_string = f'''(request-target): post {url}\nhost: {headers['Host']}\ndate: {now.strftime('%a, %d %b %Y %H:%M:%S GMT')}\ndigest: {headers['Digest']}'''\n\nsignature = pkcs1_15.new(private_key).sign(SHA256.new(signature_string.encode()))\nsignature_b64 = base64.b64encode(signature).decode()\nhttp_signature = signature_template.format(key_id, signature_b64)\nheaders['Signature'] = http_signature\n\nresponse = requests.post(base_url + url, data=json_data, headers=headers)\nprint(response.status_code, response.content)(Note: this is an Accept response to a Follow request from my mastodon.social account to my static site - searchable via mastodon.social using this link)
", "date_published": "2023-04-30T08:14:04+00:00" }, { "id": "https://jasonrbriggs.com/journal/2023/01/21/an-update-on-duckduckgo-search.html", "title": "An update on duckduckgo search", "url": "https://jasonrbriggs.com/journal/2023/01/21/an-update-on-duckduckgo-search.html", "content_text": "After reading the experiences of a number of other folk also having issues with Microsoft Bing (and thereby DuckDuckGo) indexing -- particularly [this comment](https://news.ycombinator.com/item?id=34389645) on Hacker News, I've come to the conclusion it was my fault after all.\n\nAt some point last year, I redirected my older (mostly unused) domain to this site, but using \"cloaking\". Meaning the url in the browser stays the same, and it just serves content from the new domain. Clever enough use of the old site I thought -- however, Bing somehow came to the conclusion that the old domain was the canonical one, so it's indexing pages from that domain instead. Basically I'm proxy mirroring my own site and messing up my indexing as a result.\n\nThe annoying thing in all this -- there's no indication in Bing Webmaster Tools that \"there's an exact duplicate of your content being served from [some other domain]\". Which would've been helpful to figure out where I'd gone wrong... ", "content_html": "After reading the experiences of a number of other folk also having issues with Microsoft Bing (and thereby DuckDuckGo) indexing -- particularly this comment on Hacker News, I've come to the conclusion it was my fault after all.
\nAt some point last year, I redirected my older (mostly unused) domain to this site, but using \"cloaking\". Meaning the url in the browser stays the same, and it just serves content from the new domain. Clever enough use of the old site I thought -- however, Bing somehow came to the conclusion that the old domain was the canonical one, so it's indexing pages from that domain instead. Basically I'm proxy mirroring my own site and messing up my indexing as a result.
\nThe annoying thing in all this -- there's no indication in Bing Webmaster Tools that \"there's an exact duplicate of your content being served from [some other domain]\". Which would've been helpful to figure out where I'd gone wrong...
", "date_published": "2023-01-21T20:10:21+00:00" }, { "id": "https://jasonrbriggs.com/journal/2022/12/17/salting-with-spark.html", "title": "Salting with Spark", "url": "https://jasonrbriggs.com/journal/2022/12/17/salting-with-spark.html", "content_text": "Posting this on the off-chance it's useful to someone else...\n\nOn my current project, we have a tonne of [Spark](https://spark.apache.org/) logic which needs to aggregate and (generally) sum data which is grouped by different keys, in order to then apply business rules at the record level (i.e. if the total of amount x, when grouped by a, b and c, is over a threshold then apply one calculation to each record in the group, otherwise apply another - that sort of thing). [Window functions](https://spark.apache.org/docs/latest/api/python/reference/pyspark.sql/api/pyspark.sql.Window.html) are an obvious way to do this. Consider you have employee data and want to get the total salary grouped by employment status and gender, a window example in [PySpark](https://spark.apache.org/docs/latest/api/python/index.html) might look something like this:\n\n```python\nfrom pyspark.sql import functions as f\nfrom pyspark.sql.types import IntegerType\n\nwindow = Window.partitionBy(\"employment_status\", \"gender\")\n\ndf.withColumn(\"total_salary\", f.sum(\"annual_salary\").over(window)) \\\n .select(\"first_name\", \"last_name\", \"gender\", \"employment_status\", \"annual_salary\", \"total_salary\") \\\n .orderBy(\"last_name\", \"first_name\") \\\n .show()\n\n+----------+----------+------+-----------------+-------------+------------+\n|first_name| last_name|gender|employment_status|annual_salary|total_salary|\n+----------+----------+------+-----------------+-------------+------------+\n| | | | | | 3320667.0|\n| Edwin| Abbott| M| | 139549| 8286529.0|\n| Kazuko| Abbott| F| PE| 58642| 2.4893626E7|\n```\n\nWhich works fine, but if you have a huge volume of data (say in the 100's of millions -- obviously we're not likely to be employee data now, but it was easier to find test employee data for these examples :four_leaf_clover:), and you don't have a good distribution of records in each group, then you're likely to hit issues with that skewed data -- where spark is trying to send the data from one group to a particular [executor](https://stackoverflow.com/questions/32621990/what-are-workers-executors-cores-in-spark-standalone-cluster) to accomplish the task and the executor blows as a consequence. Particularly if your data is wide (a large number of columns). \n\nEnter *salting*.\n\nThere are a number of articles on salting (like [this one](https://medium.com/appsflyerengineering/salting-your-spark-to-scale-e6f1c87dd18) on Medium), but the basic principle is to bucket the data in a group using a column with a random number (the salt) -- lets say between 1 and 100 -- so that no single group ends up with too many rows, and then do two passes, aggregation with the salt, and then without. Here's an example of the first pass:\n\n```python\nsalted_window = Window.partitionBy(\"employment_status\", \"gender\", \"salt\") \\\n .orderBy(\"employment_status\", \"gender\", \"salt\")\n\ndf.withColumn(\"salt\", f.lit(saltval).cast(IntegerType())) \\\n .withColumn(\"row_number\", row_number().over(salted_window)) \\\n .withColumn(\"salted_total_salary\", \n f.when(f.col(\"row_number\") == 1,\n sum(f.col(\"annual_salary\")).over(salted_window)).otherwise(lit(0))) \\\n .show()\n```\n\nWe're also using `row_number` in this example, so that only the first record in the group will get the salted total (otherwise we'll get the same number with each record in a group, which causes gross-up problems later). Now we *could* just sum up the salted total salary using the \"unsalted\" window:\n\n```python\nsalted_window = Window.partitionBy(\"employment_status\", \"gender\", \"salt\") \\\n .orderBy(\"employment_status\", \"gender\", \"salt\")\nwindow = Window.partitionBy(\"employment_status\", \"gender\")\n\ndf.withColumn(\"salt\", f.lit(saltval).cast(IntegerType())) \\\n .withColumn(\"row_number\", row_number().over(salted_window)) \\\n .withColumn(\"salted_total_salary\", \n f.when(f.col(\"row_number\") == 1,\n sum(f.col(\"annual_salary\")).over(salted_window))) \\\n .withColumn(\"total_salary\", f.sum(\"salted_total_salary\").over(window)) \\\n .select(\"first_name\", \"last_name\", \"gender\", \"employment_status\", \"annual_salary\", \"total_salary\") \\\n .orderBy(\"last_name\", \"first_name\") \\\n .show()\n```\n\nThe problem with this is that there's no reduction step here (ie. reducing the amount of data spark has to deal with) so immediately unsalting the data simply means all your data (still skewed), plus even more columns (the row number and the salt) is shuffled to an executor. We've not fixed the original problem at all (in fact, made it slightly worse). This should've been obvious looking at that Medium article I linked to above -- each of those examples have a filter to reduce the data volume. We missed that nugget -- but in fact, performing salted, followed by unsalted, window functions did seem to make some difference (at least some of our data sets managed to squeak through) when testing.\n\nSo what's the answer, if you need a total with each of your rows and are hitting problems with skew?\n\nDon't use window functions for these cases. Instead, stick with groupBy and agg, then join back to your original data to use the totals:\n\n```python\nfrom pyspark.sql import functions as f\nfrom pyspark.sql.types import IntegerType\n\nsaltval = f.round(f.rand() * 100)\n\ndf1 = df.withColumn(\"salt\", f.lit(saltval).cast(IntegerType())) \\\n .groupBy(\"employment_status\", \"gender\", \"salt\") \\\n .agg(f.sum(\"annual_salary\").alias(\"salted_total_salary\")) \\\n .groupBy(\"employment_status\", \"gender\") \\\n .agg(f.sum(\"salted_total_salary\").alias(\"total_salary\")) \\\n .orderBy(\"employment_status\", \"gender\") \\\n .alias(\"df1\")\n\ndf.join(df1, (df.employment_status == df1.employment_status) & \n (df.gender == df1.gender), \"leftouter\") \\\n .select(\"first_name\", \"last_name\", \"df1.gender\", \"df1.employment_status\", \"annual_salary\", \"total_salary\") \\\n .orderBy(\"last_name\", \"first_name\") \\\n .show()\n```\n\nNow we are aggregating with the salt and then without - so each step is the data reduction that spark needs to be able to deal with the volume of data in the groups (side note: a broadcast can also be useful in the above).", "content_html": "Posting this on the off-chance it's useful to someone else...
\nOn my current project, we have a tonne of Spark logic which needs to aggregate and (generally) sum data which is grouped by different keys, in order to then apply business rules at the record level (i.e. if the total of amount x, when grouped by a, b and c, is over a threshold then apply one calculation to each record in the group, otherwise apply another - that sort of thing). Window functions are an obvious way to do this. Consider you have employee data and want to get the total salary grouped by employment status and gender, a window example in PySpark might look something like this:
\nfrom pyspark.sql import functions as f\nfrom pyspark.sql.types import IntegerType\n\nwindow = Window.partitionBy(\"employment_status\", \"gender\")\n\ndf.withColumn(\"total_salary\", f.sum(\"annual_salary\").over(window)) \\\n .select(\"first_name\", \"last_name\", \"gender\", \"employment_status\", \"annual_salary\", \"total_salary\") \\\n .orderBy(\"last_name\", \"first_name\") \\\n .show()\n\n+----------+----------+------+-----------------+-------------+------------+\n|first_name| last_name|gender|employment_status|annual_salary|total_salary|\n+----------+----------+------+-----------------+-------------+------------+\n| | | | | | 3320667.0|\n| Edwin| Abbott| M| | 139549| 8286529.0|\n| Kazuko| Abbott| F| PE| 58642| 2.4893626E7|Which works fine, but if you have a huge volume of data (say in the 100's of millions -- obviously we're not likely to be employee data now, but it was easier to find test employee data for these examples 🍀), and you don't have a good distribution of records in each group, then you're likely to hit issues with that skewed data -- where spark is trying to send the data from one group to a particular executor to accomplish the task and the executor blows as a consequence. Particularly if your data is wide (a large number of columns).
\nEnter salting.
\nThere are a number of articles on salting (like this one on Medium), but the basic principle is to bucket the data in a group using a column with a random number (the salt) -- lets say between 1 and 100 -- so that no single group ends up with too many rows, and then do two passes, aggregation with the salt, and then without. Here's an example of the first pass:
\nsalted_window = Window.partitionBy(\"employment_status\", \"gender\", \"salt\") \\\n .orderBy(\"employment_status\", \"gender\", \"salt\")\n\ndf.withColumn(\"salt\", f.lit(saltval).cast(IntegerType())) \\\n .withColumn(\"row_number\", row_number().over(salted_window)) \\\n .withColumn(\"salted_total_salary\", \n f.when(f.col(\"row_number\") == 1,\n sum(f.col(\"annual_salary\")).over(salted_window)).otherwise(lit(0))) \\\n .show()We're also using row_number in this example, so that only the first record in the group will get the salted total (otherwise we'll get the same number with each record in a group, which causes gross-up problems later). Now we could just sum up the salted total salary using the \"unsalted\" window:
salted_window = Window.partitionBy(\"employment_status\", \"gender\", \"salt\") \\\n .orderBy(\"employment_status\", \"gender\", \"salt\")\nwindow = Window.partitionBy(\"employment_status\", \"gender\")\n\ndf.withColumn(\"salt\", f.lit(saltval).cast(IntegerType())) \\\n .withColumn(\"row_number\", row_number().over(salted_window)) \\\n .withColumn(\"salted_total_salary\", \n f.when(f.col(\"row_number\") == 1,\n sum(f.col(\"annual_salary\")).over(salted_window))) \\\n .withColumn(\"total_salary\", f.sum(\"salted_total_salary\").over(window)) \\\n .select(\"first_name\", \"last_name\", \"gender\", \"employment_status\", \"annual_salary\", \"total_salary\") \\\n .orderBy(\"last_name\", \"first_name\") \\\n .show()The problem with this is that there's no reduction step here (ie. reducing the amount of data spark has to deal with) so immediately unsalting the data simply means all your data (still skewed), plus even more columns (the row number and the salt) is shuffled to an executor. We've not fixed the original problem at all (in fact, made it slightly worse). This should've been obvious looking at that Medium article I linked to above -- each of those examples have a filter to reduce the data volume. We missed that nugget -- but in fact, performing salted, followed by unsalted, window functions did seem to make some difference (at least some of our data sets managed to squeak through) when testing.
\nSo what's the answer, if you need a total with each of your rows and are hitting problems with skew?
\nDon't use window functions for these cases. Instead, stick with groupBy and agg, then join back to your original data to use the totals:
\nfrom pyspark.sql import functions as f\nfrom pyspark.sql.types import IntegerType\n\nsaltval = f.round(f.rand() * 100)\n\ndf1 = df.withColumn(\"salt\", f.lit(saltval).cast(IntegerType())) \\\n .groupBy(\"employment_status\", \"gender\", \"salt\") \\\n .agg(f.sum(\"annual_salary\").alias(\"salted_total_salary\")) \\\n .groupBy(\"employment_status\", \"gender\") \\\n .agg(f.sum(\"salted_total_salary\").alias(\"total_salary\")) \\\n .orderBy(\"employment_status\", \"gender\") \\\n .alias(\"df1\")\n\ndf.join(df1, (df.employment_status == df1.employment_status) & \n (df.gender == df1.gender), \"leftouter\") \\\n .select(\"first_name\", \"last_name\", \"df1.gender\", \"df1.employment_status\", \"annual_salary\", \"total_salary\") \\\n .orderBy(\"last_name\", \"first_name\") \\\n .show()Now we are aggregating with the salt and then without - so each step is the data reduction that spark needs to be able to deal with the volume of data in the groups (side note: a broadcast can also be useful in the above).
", "date_published": "2022-12-17T17:48:27+00:00" }, { "id": "https://jasonrbriggs.com/journal/2022/08/06/leaving-duckduckgo-sort-of.html", "title": "Leaving DuckDuckGo... sort of", "url": "https://jasonrbriggs.com/journal/2022/08/06/leaving-duckduckgo-sort-of.html", "content_text": "This is a weird one. [DDG](https://duckduckgo.com) has been my search engine of choice for a number of years, so I also used it as the search engine for this site (since it's [statically generated](https://indieweb.org/static_site)). At some point over the last 3 (I think) months it stopped working - returning no results for any search criteria. Given Bing provides at least some percentage of DDG's content, I went digging in Bing's webmaster tools and found this...\n\n[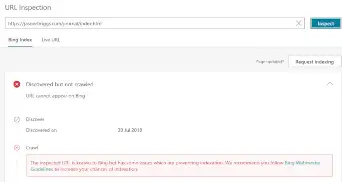](/journal/2022/08/06/bing-1.webp)\n\n(*The inspected URL is known to Bing but has some issues which are preventing indexation*)\n\nThere were a few errors reported but nothing that seems like a major issue (missing \"description\" meta, etc), and the indexation issue is even more confounding when you click on the Live Url and see...\n\n[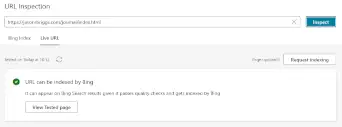](/journal/2022/08/06/bing-2.webp)\n\n(*URL can be indexed by Bing*)\n\nI fixed some of the most egregious errors, tried getting it to re-index, but regardless, nothing is searchable in DDG...\n\n[https://duckduckgo.com/?q=tkinter+site%3Ajasonrbriggs.com&t=h_&ia=web](https://duckduckgo.com/?q=tkinter+site%3Ajasonrbriggs.com&t=h_&ia=web)\n\nAnd nothing in Bing...\n\n[https://www.bing.com/search?q=tkinter+site%3Ajasonrbriggs.com](https://www.bing.com/search?q=tkinter+site%3Ajasonrbriggs.com)\n\nBut it seems Google has no problem...\n\n[https://www.google.com/search?q=tkinter+site%3Ajasonrbriggs.com](https://www.google.com/search?q=tkinter+site%3Ajasonrbriggs.com)\n\nAs a consequence, I've re-pointed the site search at google search, until I can figure something else out (perhaps [Lunr](https://lunrjs.com/)?), but for the moment it seems like I don't exist in my search engine of choice. Sigh.", "content_html": "This is a weird one. DDG has been my search engine of choice for a number of years, so I also used it as the search engine for this site (since it's statically generated). At some point over the last 3 (I think) months it stopped working - returning no results for any search criteria. Given Bing provides at least some percentage of DDG's content, I went digging in Bing's webmaster tools and found this...
\n
(The inspected URL is known to Bing but has some issues which are preventing indexation)
\nThere were a few errors reported but nothing that seems like a major issue (missing \"description\" meta, etc), and the indexation issue is even more confounding when you click on the Live Url and see...
\n
(URL can be indexed by Bing)
\nI fixed some of the most egregious errors, tried getting it to re-index, but regardless, nothing is searchable in DDG...
\nhttps://duckduckgo.com/?q=tkinter+site%3Ajasonrbriggs.com&t=h_&ia=web
\nAnd nothing in Bing...
\nhttps://www.bing.com/search?q=tkinter+site%3Ajasonrbriggs.com
\nBut it seems Google has no problem...
\nhttps://www.google.com/search?q=tkinter+site%3Ajasonrbriggs.com
\nAs a consequence, I've re-pointed the site search at google search, until I can figure something else out (perhaps Lunr?), but for the moment it seems like I don't exist in my search engine of choice. Sigh.
", "date_published": "2022-08-06T08:42:28+00:00" }, { "id": "https://jasonrbriggs.com/journal/2022/07/30/python-for-kids-2-and-latex.html", "title": "Python for Kids 2 and LaTeX", "url": "https://jasonrbriggs.com/journal/2022/07/30/python-for-kids-2-and-latex.html", "content_text": "For those who are interested, Python for Kids 2 has been completely rewritten as [LaTeX](https://www.latex-project.org/about/) (using [No Starch](https://nostarch.com)'s style); partially in text files, and partially in [Overleaf](https://overleaf.com):\n\n[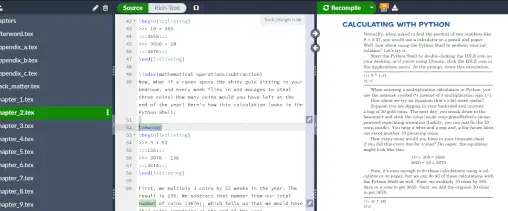](/journal/2022/07/30/overleaf.webp) \n\nOverleaf was great, particularly for the review process, but I have to say working in LaTeX is an order of magnitude better than using a Word Processor - especially when the files are backed by a git repo (which Overleaf provides) so tracking changes is easy (looking back at the history of changes in a file to see what I changed, is a big win). \n\nCan't comment on how No Starch's editorial staff found working in Overleaf (because we haven't really discussed it), but for me it was all positive...", "content_html": "For those who are interested, Python for Kids 2 has been completely rewritten as LaTeX (using No Starch's style); partially in text files, and partially in Overleaf:
\n
Overleaf was great, particularly for the review process, but I have to say working in LaTeX is an order of magnitude better than using a Word Processor - especially when the files are backed by a git repo (which Overleaf provides) so tracking changes is easy (looking back at the history of changes in a file to see what I changed, is a big win).
\nCan't comment on how No Starch's editorial staff found working in Overleaf (because we haven't really discussed it), but for me it was all positive...
", "date_published": "2022-07-30T08:34:46+00:00" }, { "id": "https://jasonrbriggs.com/journal/2022/07/29/rss-imap.html", "title": "RSS IMAP", "url": "https://jasonrbriggs.com/journal/2022/07/29/rss-imap.html", "content_text": "I've been using [feedly](https://feedly.com) since Google decided [RSS](https://www.lifewire.com/what-is-an-rss-feed-4684568) wasn't a thing any more, and have been pretty happy with it. It wasn't as good as [Google Reader](https://en.wikipedia.org/wiki/Google_Reader), but good enough. The ads are gradually becoming more invasive though, and there's less of the minimalist feel it had when I first started using it, so I've been periodically looking for an alternative.\n\nAfter finding nothing I was particularly enthused by, in the end I've decided on the slightly clunkier (certainly geekier) option: taking Tim Brownawell's Python-based [RSS -> IMAP bridge](https://github.com/tbrownaw/rss-imap), and modifying it to suit my needs.\n\nRSS-IMAP reads feed config entries from an email in an IMAP folder, and then loads the feed items as email messages (if they aren't already present in the feed-specific subfolder) - my version reads config from a yaml file instead, and uses a SQLite database to store an index of feed items that have been loaded. Using the yaml file, because I find it easier to ssh onto my raspberry pi (where this is running) and edit the feed items there; than writing a mail, sending it to myself and then copying into the RSS folder. And using a SQLite DB, because that way I can delete feed emails and they won't be re-loaded automatically. SQLite is ideal for this sort of usage, because there's only a single process writing the data, and the index lookup is fast.\n\nThe main changes can be seen here: \n[https://github.com/jasonrbriggs/rss-imap/compare/master...jasonrbriggs:rss-imap:alt?expand=1](https://github.com/jasonrbriggs/rss-imap/compare/master...jasonrbriggs:rss-imap:alt?expand=1)\n\nOr found in the \"alt\" branch of my fork: \n[https://github.com/jasonrbriggs/rss-imap/tree/alt](https://github.com/jasonrbriggs/rss-imap/tree/alt)\n\nPosting in the unlikely event someone else finds these mods useful...\n\nLong live RSS!!", "content_html": "I've been using feedly since Google decided RSS wasn't a thing any more, and have been pretty happy with it. It wasn't as good as Google Reader, but good enough. The ads are gradually becoming more invasive though, and there's less of the minimalist feel it had when I first started using it, so I've been periodically looking for an alternative.
\nAfter finding nothing I was particularly enthused by, in the end I've decided on the slightly clunkier (certainly geekier) option: taking Tim Brownawell's Python-based RSS -> IMAP bridge, and modifying it to suit my needs.
\nRSS-IMAP reads feed config entries from an email in an IMAP folder, and then loads the feed items as email messages (if they aren't already present in the feed-specific subfolder) - my version reads config from a yaml file instead, and uses a SQLite database to store an index of feed items that have been loaded. Using the yaml file, because I find it easier to ssh onto my raspberry pi (where this is running) and edit the feed items there; than writing a mail, sending it to myself and then copying into the RSS folder. And using a SQLite DB, because that way I can delete feed emails and they won't be re-loaded automatically. SQLite is ideal for this sort of usage, because there's only a single process writing the data, and the index lookup is fast.
\nThe main changes can be seen here:
\nhttps://github.com/jasonrbriggs/rss-imap/compare/master...jasonrbriggs:rss-imap:alt?expand=1
Or found in the \"alt\" branch of my fork:
\nhttps://github.com/jasonrbriggs/rss-imap/tree/alt
Posting in the unlikely event someone else finds these mods useful...
\nLong live RSS!!
", "date_published": "2022-07-29T21:31:22+00:00" }, { "id": "https://jasonrbriggs.com/journal/2022/04/29/announcing-python-for-kids-2nd-edition.html", "title": "Announcing: Python for Kids 2nd Edition", "url": "https://jasonrbriggs.com/journal/2022/04/29/announcing-python-for-kids-2nd-edition.html", "content_text": "The 2nd edition of Python for Kids is coming October 2022. What's new? Not an exhaustive list, but it has been completely refreshed for the latest version of Python, as well as being updated for the latest versions of Windows and Ubuntu. New Raspberry Pi instructions are there for those who want to use a Pi to start their coding efforts. There are new programming puzzles, updated examples, and a pretty major tidy up of the text in general. \n\nIt's spring cleaning, refurbishment and good old spit polish in book form!\n\nIf you, or someone you know, are looking to get started with programming, it's currently available from No Starch Press ([https://nostarch.com/python-kids-2nd-edition](https://nostarch.com/python-kids-2nd-edition)) on preorder, for 25% off (make sure you use coupon code PREORDER when checking out).", "content_html": "The 2nd edition of Python for Kids is coming October 2022. What's new? Not an exhaustive list, but it has been completely refreshed for the latest version of Python, as well as being updated for the latest versions of Windows and Ubuntu. New Raspberry Pi instructions are there for those who want to use a Pi to start their coding efforts. There are new programming puzzles, updated examples, and a pretty major tidy up of the text in general.
\nIt's spring cleaning, refurbishment and good old spit polish in book form!
\nIf you, or someone you know, are looking to get started with programming, it's currently available from No Starch Press (https://nostarch.com/python-kids-2nd-edition) on preorder, for 25% off (make sure you use coupon code PREORDER when checking out).
", "date_published": "2022-04-29T19:09:06+00:00" }, { "id": "https://jasonrbriggs.com/journal/2022/04/18/bbc-microbit-with-python-for-kids.html", "title": "BBC micro:bit with Python for Kids", "url": "https://jasonrbriggs.com/journal/2022/04/18/bbc-microbit-with-python-for-kids.html", "content_text": "Janick writes:\n\n> _My son got \"Python for Kids\" (the dutch translation) from Sinterklaas last december (Sinterklaas is the local Santa in Belgium_\n> _and the Netherlands). He really enjoyed it! The weeks following he read and coded almost every day until he finished the book._\n> _Some days after, I mentioned we could investigate if he could use the micro:bit he got the year before to control his games._ \n> _He was really into this idea and we looked for python packages that could make this possible. We didn't find any, and because_ \n> _the bluetooth APIs are a bit difficult to get started with for a kid, I created one myself: [https://github.com/janickr/kaspersmicrobit](https://github.com/janickr/kaspersmicrobit)._\n> _We both find the result really fun and engaging! It makes the games even more impressive and attractive for other kids_ \n> _(like his older sisters). I hope you like it too!_\n\nGlad your son enjoyed the book, and the micro:bit controller looks very cool -- I particularly like the 2-player adaptation of the Bounce game you came up with in the video:\n\n", "content_html": "Janick writes:
\n\n\nMy son got \"Python for Kids\" (the dutch translation) from Sinterklaas last december (Sinterklaas is the local Santa in Belgium\nand the Netherlands). He really enjoyed it! The weeks following he read and coded almost every day until he finished the book.\nSome days after, I mentioned we could investigate if he could use the micro:bit he got the year before to control his games. \nHe was really into this idea and we looked for python packages that could make this possible. We didn't find any, and because \nthe bluetooth APIs are a bit difficult to get started with for a kid, I created one myself: https://github.com/janickr/kaspersmicrobit.\nWe both find the result really fun and engaging! It makes the games even more impressive and attractive for other kids \n(like his older sisters). I hope you like it too!
\n
Glad your son enjoyed the book, and the micro:bit controller looks very cool -- I particularly like the 2-player adaptation of the Bounce game you came up with in the video:
\n
 The Vietnamese translation of Python for Kids is now available from the publisher Sputnik Edu. I think that's something in the region of 12 languages in total now (including English)! 👍
The Vietnamese translation of Python for Kids is now available from the publisher Sputnik Edu. I think that's something in the region of 12 languages in total now (including English)! 👍
I've built a Docker image for running single-node Spark and Hadoop (one worker) on a Raspberry Pi, since I couldn't find anything to experiment with. Certainly not suitable for anything other than experimentation, but the image can be found on Docker hub here:
\nhub.docker.com/repository/docker/jasonrbriggs/pi-spark
\nThe \"source\", such that it is (dockerfile, etc), can be access from radicle via this URN:
\nrad:git:hwd1yreyw4xcjarwtb4yuxtsd5dmip9wx9fr9tomjib1mmtkmojnicnn4boI wanted to boot my Raspberry Pi 4 from an external SSD connected via a USB-to-SATA cable. According to Jeff Geerling's video, it's pretty straightforward using the latest version of the firmware - but try as I might I couldn't get it to start. Tried re-imaging the SSD; also used the SD card copier, to copy the SD contents across to the SSD; but regardless it didn't seem to detect on boot (it was accessible after starting up using the SD, so I knew it probably wasn't a powering issue).
\nAfter much muddling around, came across rpi-eeprom-config, and realised that BOOT_ORDER was was set to 0x1 -- according to this page that's SD card mode. Also according to that page, the default is supposed to be 0xf41 (try SD, if not found, try USB). Ran sudo rpi-eeprom-config --edit, changed the value, saved, rebooted and voila, the SSD was bootable, and has been seemlessly working since then.
I'm sure this info has been posted elsewhere, but given I couldn't find it, posting here in case it's of use to someone else.
", "date_published": "2021-02-05T22:52:28+00:00" }, { "id": "https://jasonrbriggs.com/journal/2021/01/30/breaking-out-of-loops.html", "title": "Breaking out of loops", "url": "https://jasonrbriggs.com/journal/2021/01/30/breaking-out-of-loops.html", "content_text": "Sherry W writes (excerpted):\n\n> _Excellent book so far for my grandson._\n>\n> _On page 78 should it read?:_\n>\n> _while True:_ \n> _lots of code here_ \n> _lots of code here_ \n> _lots of code here_ \n> _if some value == False_ \n> _break_ \n>\n> _Book is written very well for that age group. It’s great to have a book that is able to explain concepts with simple examples._\n\nThe example on page 78 is not supposed to be executable code (obviously the text \"lots of code here\" repeated 3 times isn't), so it doesn't actually matter if the condition is \"`some_value == False`\" or \"`some_value == True`\". If I was going to write a runnable version of the example, it might look something like this:\n\n```python\nsome_value = True\nwhile True:\n print(\"aaaa\")\n print(\"bbbb\")\n print(\"cccc\")\n if some_value == True:\n break \n```\n\nWhich, if it was run, would print the following just once:\n\n```\naaaa\nbbbb\ncccc\n```\n\nBut you could use True or False in the above example (on the first line and the second-to-last line), and it would work just as well.\n\nHowever a shortcut, not mentioned in the book (because I think simplicity and clarity is better for beginners), is that when you're checking for `True`, you can omit the \"`== True`\" altogether:\n\n```python\nsome_value = True\nwhile True:\n print(\"aaaa\")\n print(\"bbbb\")\n print(\"cccc\")\n if some_value:\n break \n```", "content_html": "Sherry W writes (excerpted):
\n\n\nExcellent book so far for my grandson.
\nOn page 78 should it read?:
\nwhile True:
\n
\n lots of code here
\n lots of code here
\n lots of code here
\n if some value == False
\n breakBook is written very well for that age group. It’s great to have a book that is able to explain concepts with simple examples.
\n
The example on page 78 is not supposed to be executable code (obviously the text \"lots of code here\" repeated 3 times isn't), so it doesn't actually matter if the condition is \"some_value == False\" or \"some_value == True\". If I was going to write a runnable version of the example, it might look something like this:
some_value = True\nwhile True:\n print(\"aaaa\")\n print(\"bbbb\")\n print(\"cccc\")\n if some_value == True:\n break Which, if it was run, would print the following just once:
\naaaa\nbbbb\nccccBut you could use True or False in the above example (on the first line and the second-to-last line), and it would work just as well.
\nHowever a shortcut, not mentioned in the book (because I think simplicity and clarity is better for beginners), is that when you're checking for True, you can omit the \"== True\" altogether:
some_value = True\nwhile True:\n print(\"aaaa\")\n print(\"bbbb\")\n print(\"cccc\")\n if some_value:\n break Suranga writes:
\n\n\nMy son and I have been learning Python with your great book. Unfortunately, we hit an issue with Colorchooser -\nthe problem appears identical to this one: https://jasonrbriggs.com/journal/2013/05/01/tkinter-colorchooser-problems.html\nIn the solution, you suggest we revisit Chapter 1 but can see no mention of a way to ensure IDLE is launched with No Subprocesses.\nHave we missed something here? Perhaps there was an earlier version of the book that did not contain this? (ours is the Tenth Printing).\nThanks for any guidance you can provide!
\n
No, you haven't missed anything. In subsequent printings of the book, my advice about using \"No subprocess\" has been removed -- that mode is no longer valid with the versions of Python 3 released since Python for Kids came out in 2012.
\nInterestingly, despite the fact all the code in the original print was tested by multiple people (including me!), I can't now find a version of python where from tkinter import * actually results in colorchooser.askcolor() working properly. So in yet later printings (some time after Jan 2017), I changed the instructions to reflect that fact that colorchooser is not imported by default when using import *.
This is now the corrected code:
\nfrom tkinter import *\nfrom tkinter import colorchooser\ntk = Tk()\ntk.update()\ncolorchooser.askcolor()I was reading Tim Bray's recent blog posts (here and here) about his Topfew utility with interest, and wondered how my go-to systems programming language (Nim) stacks up compared to Go. I knocked up a quick and dirty implementation and then ran against a 900MB access_log from my own site. A minute or so later I hit CTRL+C, realising my quick and dirty implementation was (a) not quick at all, and (b) perhaps a bit too \"dirty\". ಠ_ಠ
\nOnce I changed from the naive read everything into memory approach, to using Nim's streams, I ended up with something slightly more acceptable. Caveat: not really optimised (well... apart from compiling with -d:release --passC:-mcpu=native --boundChecks:off flags), lazily developed, probably still naive, but at least has border-line acceptable performance (Github).
Results on my laptop (with an approx 1.5 million line access_log):
\n| \n | Elapsed | \nUser | \nSystem | \nvs Go | \n
|---|---|---|---|---|
| Tim's topfew | \n2.68 | \n3.86 | \n0.41 | \n1.0 | \n
| ls/uniq/sort | \n9.10 | \n1.76 | \n0.26 | \n3.4 | \n
| Nim | \n3.91 | \n3.65 | \n0.25 | \n1.5 | \n
1.5x isn't brilliant, but it's not bad considering the minimal amount of effort I spent on it. But that led me to wonder, what about Python performance? Another Q&D implementation later (and this time I haven't bothered to dig into the performance at all)...
\n| \n | Elapsed | \nUser | \nSystem | \nvs Go | \n
|---|---|---|---|---|
| Tim's topfew | \n2.68 | \n3.86 | \n0.41 | \n1.0 | \n
| ls/uniq/sort | \n9.10 | \n1.76 | \n0.26 | \n3.4 | \n
| Nim | \n3.91 | \n3.65 | \n0.25 | \n1.5 | \n
| Python | \n8.57 | \n7.77 | \n0.79 | \n3.2 | \n
Not much better than the uniq/sort version, but the python version is arguably a little more readable than Nim. One interesting difference between Python and Nim -- the Python version does read the whole file into memory before tokenising...
\nwith open(filename) as f:\n for line in f.readlines():\n ......yet the performance was significantly better than my earlier naive Nim implementation which also read the whole file. So it's not just the right tool for the job, but the right technique for the tool.
\nDo I feel like dusting off the rather rusty Haskell skills though...?
", "date_published": "2020-07-05T10:02:33+01:00" }, { "id": "https://jasonrbriggs.com/journal/2020/05/30/problem-with-bouncing-ball.html", "title": "Problem with bouncing ball", "url": "https://jasonrbriggs.com/journal/2020/05/30/problem-with-bouncing-ball.html", "content_text": "Lennier M writes:\n\n> _I am on page 202 of your book, but when I followed your instructions, the ball stopped moving, instead of moving in multiple directions._\n> _Here is my code:_\n>\n> class Ball: \n> def \\_\\_init\\_\\_(self, canvas, color): \n> self.canvas = canvas \n> self.id = canvas.create_oval(10, 10, 25, 25, fill=color) \n> self.canvas.move(self.id, 245, 100) \n> starts = [-3, -2, -1, 1, 2, 3, ] \n> random.shuffle(starts) \n> self.x = starts[0] \n> self.y = -3 \n> self.canvas_width = self.canvas.winfo_width \n> self.canvas_height = self.canvas.winfo_height() \n> def draw(self): \n> self.canvas.move(self.id, self.x, self.y) \n> pos = self.canvas.coords(self.id) \n> if pos[1] <= 0: \n> self.y = 1 \n> if pos[3] >= self.canvas_height: \n> self.y = -1 \n> if pos[0] <= 0: \n> self.x = 3 \n> if pos[2] >= self.canvas_width: \n> self.x = -3 \n> \n> _please help_\n\nIf I run your code I get the following error:\n\n```python\nTraceback (most recent call last):\n File \"test.py\", line 40, inLennier M writes:
\n\n\nI am on page 202 of your book, but when I followed your instructions, the ball stopped moving, instead of moving in multiple directions.\nHere is my code:
\nclass Ball:
\n
\n def __init__(self, canvas, color):
\n self.canvas = canvas
\n self.id = canvas.create_oval(10, 10, 25, 25, fill=color)
\n self.canvas.move(self.id, 245, 100)
\n starts = [-3, -2, -1, 1, 2, 3, ]
\n random.shuffle(starts)
\n self.x = starts[0]
\n self.y = -3
\n self.canvas_width = self.canvas.winfo_width
\n self.canvas_height = self.canvas.winfo_height()
\n def draw(self):
\n self.canvas.move(self.id, self.x, self.y)
\n pos = self.canvas.coords(self.id)
\n if pos[1] <= 0:
\n self.y = 1
\n if pos[3] >= self.canvas_height:
\n self.y = -1
\n if pos[0] <= 0:
\n self.x = 3
\n if pos[2] >= self.canvas_width:
\n self.x = -3please help
\n
If I run your code I get the following error:
\nTraceback (most recent call last):\n File \"test.py\", line 40, in <module>\n ball.draw()\n File \"test.py\", line 26, in draw\n if pos[2] >= self.canvas_width:\nTypeError: '>=' not supported between instances of 'float' and 'method'So that tells us the line which is failing, but why?
\nIf you look at these two lines, hopefully you'll see the difference (and the reason for your problem):
\n self.canvas_width = self.canvas.winfo_width\n self.canvas_height = self.canvas.winfo_height()The missing brackets on the first line mean that you haven't actually called the winfo_width function (or method). So self.canvas_width isn't a number of pixels - it's actually a reference to the function itself. If we added a print statement at that point in the code it would be even more obvious...
print(self.canvas_width)\n<bound method Misc.winfo_width of <tkinter.Canvas object .!canvas>>\nprint(self.canvas_height)\n400This is the reason why comparing pos[2] (which is a number - to be exact it's a floating point number) with self.canvas_width (which is the reference to a function/method) comes back with the error message: \"'>=' not supported between instances of 'float' and 'method'\".
If you add the missing brackets, you'll hopefully find the ball moves as expected.
", "date_published": "2020-05-30T20:11:32+01:00" }, { "id": "https://jasonrbriggs.com/journal/2020/05/03/online-supermarket-delivery-in-the-uk-needs-to-evolve.html", "title": "Online supermarket delivery in the UK needs to evolve", "url": "https://jasonrbriggs.com/journal/2020/05/03/online-supermarket-delivery-in-the-uk-needs-to-evolve.html", "content_text": "We managed to get a Tesco's delivery last week, which was a challenge - the best we've been do so far is about one delivery every two weeks or so (from different supermarkets). But that basically means sitting online for hours hitting the refresh button to see if a slot becomes available.\n\n_Hunter-gathering in the twenty-first century..._\n\nA couple of hours after our delivery had arrived, I happened to look out the window and see another Tescos delivery being dropped off about two doors down. So not only dumb [UX](https://en.wikipedia.org/wiki/User_experience), but from a logistics perspective, poor design as well.\n\nWhat would make far more sense to me, particularly in this time of lockdown (probably after as well), is you load up your basket with your shopping, then specify half day slots when you'll be at home. i.e. \"here's the 30 things I want, and I can be home for delivery any time Monday to Sunday for the next two weeks\". or \"I can be home for delivery on Friday morning, Saturday morning, and all day Sunday\". Periodically the supermarket runs an algorithm to find the optimal delivery for each order (and obviously you don't get charged if you don't get a delivery) -- perhaps with some prioritisation for those who've been waiting longer for their delivery slot.\n\nThere's nothing massively complicated about this as an algorithm - group addresses in the same street which have an intersecting time period. Then group addresses with close proximity (maybe half a mile or so). Then look for addresses slightly farther apart, but still close enough that delivery can be optimised (half a mile up to a couple of miles) - perhaps some of those can be grouped with one of the first two groups as well. Give each of these delivery groups a certain amount of points. You then rank the deliveries by their points, and by the age of the oldest order in the group -- ungrouped orders would just be ranked by their age -- and send out notifications to the confirmed orders. Discount delivery charges for grouped orders, and if there are any remaining slots available, open them up to adhoc deliveries with a slightly higher charge.\n\nThere's more complexity to take into account, of course - the number of delivery vans versus the number of deliveries per van, distance to the supermarket/depo, etc. But still, the result is likely an improved user experience for everyone, better for the environment and probably more cost effective for the supermarkets.", "content_html": "We managed to get a Tesco's delivery last week, which was a challenge - the best we've been do so far is about one delivery every two weeks or so (from different supermarkets). But that basically means sitting online for hours hitting the refresh button to see if a slot becomes available.
\nHunter-gathering in the twenty-first century...
\nA couple of hours after our delivery had arrived, I happened to look out the window and see another Tescos delivery being dropped off about two doors down. So not only dumb UX, but from a logistics perspective, poor design as well.
\nWhat would make far more sense to me, particularly in this time of lockdown (probably after as well), is you load up your basket with your shopping, then specify half day slots when you'll be at home. i.e. \"here's the 30 things I want, and I can be home for delivery any time Monday to Sunday for the next two weeks\". or \"I can be home for delivery on Friday morning, Saturday morning, and all day Sunday\". Periodically the supermarket runs an algorithm to find the optimal delivery for each order (and obviously you don't get charged if you don't get a delivery) -- perhaps with some prioritisation for those who've been waiting longer for their delivery slot.
\nThere's nothing massively complicated about this as an algorithm - group addresses in the same street which have an intersecting time period. Then group addresses with close proximity (maybe half a mile or so). Then look for addresses slightly farther apart, but still close enough that delivery can be optimised (half a mile up to a couple of miles) - perhaps some of those can be grouped with one of the first two groups as well. Give each of these delivery groups a certain amount of points. You then rank the deliveries by their points, and by the age of the oldest order in the group -- ungrouped orders would just be ranked by their age -- and send out notifications to the confirmed orders. Discount delivery charges for grouped orders, and if there are any remaining slots available, open them up to adhoc deliveries with a slightly higher charge.
\nThere's more complexity to take into account, of course - the number of delivery vans versus the number of deliveries per van, distance to the supermarket/depo, etc. But still, the result is likely an improved user experience for everyone, better for the environment and probably more cost effective for the supermarkets.
", "date_published": "2020-05-03T12:38:42+01:00" }, { "id": "https://jasonrbriggs.com/journal/2020/04/14/long-and-short-dashes.html", "title": "Long and short dashes", "url": "https://jasonrbriggs.com/journal/2020/04/14/long-and-short-dashes.html", "content_text": "Jan vK writes:\n\n> _here's an example from your book that gives an error:_ \n> _count_down_by_twos = list(range(40, 10, −2))_ \n> _SyntaxError: invalid character in identifier_ \n> _please inform me how to solve this problem_\n\nIt looks like you might have copied-and-pasted the code? Perhaps from the digital version of the book? It looks like the -2 in your example is actually a hyphen (i.e. a long dash −) instead of a minus (i.e. a short dash -). So if I try the version of the code you sent, I get the same error:\n\n```python\n>>> count_down_by_twos = list(range(40, 10, −2))\n File \"Jan vK writes:
\n\n\nhere's an example from your book that gives an error:
\n
\ncount_down_by_twos = list(range(40, 10, −2))
\nSyntaxError: invalid character in identifier
\nplease inform me how to solve this problem
It looks like you might have copied-and-pasted the code? Perhaps from the digital version of the book? It looks like the -2 in your example is actually a hyphen (i.e. a long dash −) instead of a minus (i.e. a short dash -). So if I try the version of the code you sent, I get the same error:
\n>>> count_down_by_twos = list(range(40, 10, −2))\n File \"<stdin>\", line 1\n count_down_by_twos = list(range(40, 10, −2))\n ^\nSyntaxError: invalid character in identifierHowever, if I try with the correct character, there's no error:
\n>>> count_down_by_twos = list(range(40, 10, -2))\n>>> The next question you might ask is what does \"invalid character in identifier\" actually mean? An identifier is the name of something (the name of a keyword, a variable, a function or a class, and so on) -- valid identifiers are a sequence of letters (characters), digits and underscores. In effect you're getting that error message because python doesn't recognise \"−2\" (a long dash followed by 2) as any recognisable keyword, or variable, or anything resembling a valid identifier.
\nHope that helps.
", "date_published": "2020-04-14T20:00:17+01:00" }, { "id": "https://jasonrbriggs.com/journal/2020/01/17/icann-corruption.html", "title": "ICANN corruption", "url": "https://jasonrbriggs.com/journal/2020/01/17/icann-corruption.html", "content_text": "Belatedly... this [article](https://www.theregister.co.uk/2020/01/07/icann_verisign_fees/) about ICANN & dot-com price increases (which does look rather like ICANN corruption, in my opinion), annoyed me more than I can properly express, despite the fact that initially (first few years) the 7% increase will still be less than I'm paying for [dot-nz](https://dnc.org.nz/) domain names. This is pretty obvious profiteering by Verisign, and I worry that this will trickle out from the US to domain names for other countries, inevitably turning the ownership of a domain name from something that's a petty cash expense into a real, and significant, cost. It's particularly concerning if you take into consideration similar news in the [dot-org](https://blog.mozilla.org/blog/2019/12/03/questions-about-org/) [space](https://www.eff.org/press/releases/eff-icann-stop-org-domain-registry-sale-private-equity-firm).\n\nIt irritated enough that I started [looking](https://www.opennic.org/) [at](https://www.namecoin.org/) [alternatives](https://emercoin.com/en/emerdns). However, none of the blockchain domain name options look like a particular economic, straightforward, sure-fire win (paticularly not for a non-technical audience) - even OpenNIC, which is the closest tech to the incumbent, would require jumping through additional hoops because I don't believe my current hosting provider supports DNS alternatives - on their forums, I can't find any mention of OpenNIC apart from a note on a \"Rejected Feature Proposals\" forum, back in 2007, about it being a stale project.\n\nMaybe the global Internet community will eventually route its way around the \"damage\" by selecting a generally acceptable alternative. Or a privacy-focused browser maker like Mozilla will come up with (and promote) a viable domain name system that the other browser makers will have to implement or be left behind.\n\nIn the meantime, perhaps I'll look at redirecting my primary domain elsewhere and route around the problem myself, before the name comes up for renewal in a few years time...", "content_html": "Belatedly... this article about ICANN & dot-com price increases (which does look rather like ICANN corruption, in my opinion), annoyed me more than I can properly express, despite the fact that initially (first few years) the 7% increase will still be less than I'm paying for dot-nz domain names. This is pretty obvious profiteering by Verisign, and I worry that this will trickle out from the US to domain names for other countries, inevitably turning the ownership of a domain name from something that's a petty cash expense into a real, and significant, cost. It's particularly concerning if you take into consideration similar news in the dot-org space.
\nIt irritated enough that I started looking at alternatives. However, none of the blockchain domain name options look like a particular economic, straightforward, sure-fire win (paticularly not for a non-technical audience) - even OpenNIC, which is the closest tech to the incumbent, would require jumping through additional hoops because I don't believe my current hosting provider supports DNS alternatives - on their forums, I can't find any mention of OpenNIC apart from a note on a \"Rejected Feature Proposals\" forum, back in 2007, about it being a stale project.
\nMaybe the global Internet community will eventually route its way around the \"damage\" by selecting a generally acceptable alternative. Or a privacy-focused browser maker like Mozilla will come up with (and promote) a viable domain name system that the other browser makers will have to implement or be left behind.
\nIn the meantime, perhaps I'll look at redirecting my primary domain elsewhere and route around the problem myself, before the name comes up for renewal in a few years time...
", "date_published": "2020-01-18T13:43:59+00:00" }, { "id": "https://jasonrbriggs.com/journal/2019/09/22/problems-with-restarting-the-game.html", "title": "Problems with restarting the game", "url": "https://jasonrbriggs.com/journal/2019/09/22/problems-with-restarting-the-game.html", "content_text": "Serhii writes (excerpted from two emails):\n\n> _I teach programming lessons for the pupils._\n> _We try to do restart button for the \"Bounce\" as it follows:_ \n> _[jasonrbriggs.com/journal/2014/09/03/restarting-the-game.html](https://jasonrbriggs.com/journal/2014/09/03/restarting-the-game.html)_ \n> _...there is a problem in \"command=restart\"._\n\nIf I run your code I get the following error:\n\n```python\nTraceback (most recent call last):\n File \"game1.py\", line 105, inSerhii writes (excerpted from two emails):
\n\n\nI teach programming lessons for the pupils.\nWe try to do restart button for the \"Bounce\" as it follows:
\n
\njasonrbriggs.com/journal/2014/09/03/restarting-the-game.html
\n...there is a problem in \"command=restart\".
If I run your code I get the following error:
\nTraceback (most recent call last):\n File \"game1.py\", line 105, in <module>\n game.add_restart()\n File \"game1.py\", line 86, in add_restart\n self.restart_button = Button(tk, text=\"Click to Restart Game\", command=restart, bg=\"green\")\nNameError: name 'restart' is not definedLooking at your code...
\n def add_restart(self):\n self.restart_button = Button(tk, text=\"Click to Restart Game\", command=restart, bg=\"green\")\n self.restart_button.pack()...the problem is you don't actually have a function called restart anywhere - which explains the error message \"name 'restart' is not defined\". The easiest way to fix this, is to define that function inside your Game class, in which case the above function should actually be:
def add_restart(self):\n self.restart_button = Button(tk, text=\"Click to Restart Game\", command=self.restart, bg=\"green\")\n self.restart_button.pack()self there)\nThe restart function itself should remove the restart button from the screen, move the paddle and ball back to the starting position, and reset the score. I suggest you create a simple function first, just to prove the button works:
\n def restart(self):\n print(\"Restart the game!\")If you see \"Restart the game!\" printed when clicking the button, you know you're good to start adding the code to do the actual restart (you might also find this post useful: journal/2018/03/04/restarting-the-bounce-game-revisited). The other thing you might want to think about changing, is to only add the restart button if the game is over (so that's a small change to the while loop at the bottom).
Hope that helps.
", "date_published": "2019-09-22T10:15:27+01:00" }, { "id": "https://jasonrbriggs.com/journal/2019/09/07/idle3-on-ubuntu.html", "title": "IDLE3 on Ubuntu", "url": "https://jasonrbriggs.com/journal/2019/09/07/idle3-on-ubuntu.html", "content_text": "Chris K writes (excerpted):\n\n> _I'm teaching myself and home educating my three young daughters at the same time. Just a little bit every day (excepting Sunday which is entirely reserved_\n> _for pancakes and not inter-computery-things) . Thank you for providing the opportunity for me to introduce the subject of computer programming in a fun way._ \n> _Anyhow, we hit a snag early on that does not seem to get a mention on the publishers site or your blog. When instructed to search for IDLE on the Ubuntu_\n> _software centre nothing of relevance was listed. I had one of the girls do it and she was very disappointed..._ \n> _...I've done some homework and followed [vitux.com/how-to-install-idle-python-ide-on-your-ubuntu](https://vitux.com/how-to-install-idle-python-ide-on-your-ubuntu/) instructions on installing idle3, which worked._\n> _So we are all set to go today._\n> \n> _I don't know how useful this feedback is to you but this is an opportunity to express my appreciation for all your hard work and skill, so I'm taking it._\n\nThe next re-print of Python for Kids will include updated instructions for installing IDLE3 on Ubuntu - which obviously doesn't help anyone reading the current print\nof the book. My steps are pretty similar to the link you've referenced:\n\n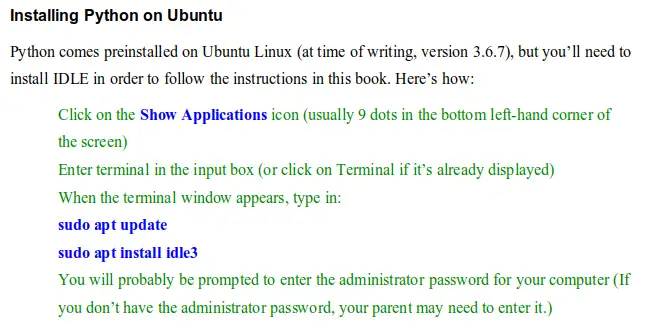 \n\nThanks for the email - it's a good prompting to put something on my site, which others in the same position might come across.\n", "content_html": "Chris K writes (excerpted):
\n\n\nI'm teaching myself and home educating my three young daughters at the same time. Just a little bit every day (excepting Sunday which is entirely reserved\nfor pancakes and not inter-computery-things) . Thank you for providing the opportunity for me to introduce the subject of computer programming in a fun way.
\n
\nAnyhow, we hit a snag early on that does not seem to get a mention on the publishers site or your blog. When instructed to search for IDLE on the Ubuntu\nsoftware centre nothing of relevance was listed. I had one of the girls do it and she was very disappointed...
\n...I've done some homework and followed vitux.com/how-to-install-idle-python-ide-on-your-ubuntu instructions on installing idle3, which worked.\nSo we are all set to go today.I don't know how useful this feedback is to you but this is an opportunity to express my appreciation for all your hard work and skill, so I'm taking it.
\n
The next re-print of Python for Kids will include updated instructions for installing IDLE3 on Ubuntu - which obviously doesn't help anyone reading the current print\nof the book. My steps are pretty similar to the link you've referenced:
\n
Thanks for the email - it's a good prompting to put something on my site, which others in the same position might come across.
", "date_published": "2019-09-07T13:50:54+01:00" }, { "id": "https://jasonrbriggs.com/journal/2019/08/02/not-the-normal-knock-off.html", "title": "Not the normal knock-off", "url": "https://jasonrbriggs.com/journal/2019/08/02/not-the-normal-knock-off.html", "content_text": "Usually on Amazon, we see [Python for Kids](https://jasonrbriggs.com/python-for-kids) knock-offs which are an exact copy of the book, with cruddy printing and/or binding. [No Starch](https://nostarch.com/) have a clever binding which allows books to open flat, without falling apart after reading a couple of chapters (clever enough that a few people thought it was actually a failure in the glue) - so these were pretty obviously cheap copies, even without the often misprinted and missing pages.\n\nHowever, an eagle-eyed reader recently notified No Starch of a new type of knock-off -- where they have slightly rewritten the text (I assume just enough to fool a copyright-checking algorithm), and included content from (I think) other sources, to make it even less likely that any automation would flag the book.\n\nFor example, here's an excerpt from Python for Kids...\n\n\n\nAnd here's the dodgy knock off...\n\n\n\nErm... what the heck is a \"Trump String\"? \n\nHere's another one from PfK:\n\n\n\nAnd here's the knock off again...\n\n\n\nYeah... way to rewrite it to be more [boooooooring](https://giphy.com/gifs/reaction-uBmiwcS1lGoHGHp0b7/fullscreen), Book Pirates! \n\nThe code examples are pretty much exactly the same in the knock-off (at least the examples I checked) - if badly formatted (including misprinted wingdings characters and other artifacts).\n\nSo, the first part of the book is basically a slightly (and extremely poorly) rewritten knock-off of mine. The second part of the book has things like bubble sort, insertion sort and...\n\n\n\n...because every self-respecting kid needs to how to write a sorting algorithm (by just looking at the code) and how to use numpy and pandas for page-rank???\n\nAnd from there, on to games like Hangman, but written with Python2 and incorrectly formatted as well...\n\n\n\nA garbage knock-off, and 29 five-star reviews in a couple of weeks, no less (I assume paid for). Interestingly, I clicked through a few of the other reviews by those same reviewers and found more poorly written texts. It's an Amazonian (sic) nest of crappy Python books!\n\nTick tick tick. I wonder how long it'll take Amazon to catch on... \n", "content_html": "Usually on Amazon, we see Python for Kids knock-offs which are an exact copy of the book, with cruddy printing and/or binding. No Starch have a clever binding which allows books to open flat, without falling apart after reading a couple of chapters (clever enough that a few people thought it was actually a failure in the glue) - so these were pretty obviously cheap copies, even without the often misprinted and missing pages.
\nHowever, an eagle-eyed reader recently notified No Starch of a new type of knock-off -- where they have slightly rewritten the text (I assume just enough to fool a copyright-checking algorithm), and included content from (I think) other sources, to make it even less likely that any automation would flag the book.
\nFor example, here's an excerpt from Python for Kids...
\n
And here's the dodgy knock off...
\n
Erm... what the heck is a \"Trump String\"?
\nHere's another one from PfK:
\n
And here's the knock off again...
\n
Yeah... way to rewrite it to be more boooooooring, Book Pirates!
\nThe code examples are pretty much exactly the same in the knock-off (at least the examples I checked) - if badly formatted (including misprinted wingdings characters and other artifacts).
\nSo, the first part of the book is basically a slightly (and extremely poorly) rewritten knock-off of mine. The second part of the book has things like bubble sort, insertion sort and...
\n
...because every self-respecting kid needs to how to write a sorting algorithm (by just looking at the code) and how to use numpy and pandas for page-rank???
\nAnd from there, on to games like Hangman, but written with Python2 and incorrectly formatted as well...
\n
A garbage knock-off, and 29 five-star reviews in a couple of weeks, no less (I assume paid for). Interestingly, I clicked through a few of the other reviews by those same reviewers and found more poorly written texts. It's an Amazonian (sic) nest of crappy Python books!
\nTick tick tick. I wonder how long it'll take Amazon to catch on...
", "date_published": "2019-08-02T14:26:36+12:00" }, { "id": "https://jasonrbriggs.com/journal/2019/07/23/string-formatting.html", "title": "String formatting", "url": "https://jasonrbriggs.com/journal/2019/07/23/string-formatting.html", "content_text": "Lou O writes:\n\n> _Hi Jason,_\n> _Read a few good reviews of your book on Amazon._ \n> _One of the reviews pointed out \"The explanation of String formatting needs to be updated. We don't do embedded values using %s anymore._\n> _I recommend skipping the chapters on Turtle Graphics and tkinter._\n> _The introductory chapter on classes and objects is not bad, but the topic is beyond what most kids will need, and they should really focus on imperative / procedural_\n> _programming first using just lists and dictionaries as their basic data structures.\"_ \n> _And I was wondering if those points had been taken into account and updated since then._\n\nIn terms of string formatting, the reviewer is correct but, on the other hand, % formatting hasn't actually been deprecated yet. From the official Python 3 [documentation](https://docs.python.org/3/library/stdtypes.html#printf-style-string-formatting):\n\n> The formatting operations described here exhibit a variety of quirks that lead to a number of common errors (such as failing to display tuples and dictionaries\n> correctly). Using the newer formatted string literals, the str.format() interface, or template strings may help avoid these errors. Each of these alternatives\n> provides their own trade-offs and benefits of simplicity, flexibility, and/or extensibility. \n\nI have thought about updating the section on formatting though, just because using `str.format` is the more accepted/modern method -- but this will probably have to wait for a second edition, or perhaps the next major reprint.\n\nIn terms of classes and objects, I don't agree at all. When originally writing the book, I thought rather hard about whether it was worth going into the complexity of that topic and, in the end, came to the conclusion that there is too much in Python which **is** object-oriented, and would be more confusing to explain without at least covering the basics (IMHO).\n\nAnd finally, in regard to the comment about skipping the chapters on turtle and tkinter... sure, if they want a dry book on programming fundamentals, with nothing fun for a kid to experiment with -- one that they will then put down 10 minutes after opening and never return to -- by all means, skip those chapters.\n\nFor everyone else: will your child use the turtle and/or tkinter modules in the future? Probably not. But are they a useful tool to learn how to use those fundamental programming concepts (without needing to install any complicated third party libraries)? Personally, I believe so.", "content_html": "Lou O writes:
\n\n\nHi Jason,\nRead a few good reviews of your book on Amazon.
\n
\nOne of the reviews pointed out \"The explanation of String formatting needs to be updated. We don't do embedded values using %s anymore.\nI recommend skipping the chapters on Turtle Graphics and tkinter.\nThe introductory chapter on classes and objects is not bad, but the topic is beyond what most kids will need, and they should really focus on imperative / procedural\nprogramming first using just lists and dictionaries as their basic data structures.\"
\nAnd I was wondering if those points had been taken into account and updated since then.
In terms of string formatting, the reviewer is correct but, on the other hand, % formatting hasn't actually been deprecated yet. From the official Python 3 documentation:
\n\n\nThe formatting operations described here exhibit a variety of quirks that lead to a number of common errors (such as failing to display tuples and dictionaries\ncorrectly). Using the newer formatted string literals, the str.format() interface, or template strings may help avoid these errors. Each of these alternatives\nprovides their own trade-offs and benefits of simplicity, flexibility, and/or extensibility.
\n
I have thought about updating the section on formatting though, just because using str.format is the more accepted/modern method -- but this will probably have to wait for a second edition, or perhaps the next major reprint.
In terms of classes and objects, I don't agree at all. When originally writing the book, I thought rather hard about whether it was worth going into the complexity of that topic and, in the end, came to the conclusion that there is too much in Python which is object-oriented, and would be more confusing to explain without at least covering the basics (IMHO).
\nAnd finally, in regard to the comment about skipping the chapters on turtle and tkinter... sure, if they want a dry book on programming fundamentals, with nothing fun for a kid to experiment with -- one that they will then put down 10 minutes after opening and never return to -- by all means, skip those chapters.
\nFor everyone else: will your child use the turtle and/or tkinter modules in the future? Probably not. But are they a useful tool to learn how to use those fundamental programming concepts (without needing to install any complicated third party libraries)? Personally, I believe so.
", "date_published": "2019-07-23T08:57:31+12:00" }, { "id": "https://jasonrbriggs.com/journal/2019/05/08/bouncing-in-polski.html", "title": "Bouncing in Polski", "url": "https://jasonrbriggs.com/journal/2019/05/08/bouncing-in-polski.html", "content_text": "Marzena writes:\n\n> _I'm writing to you because neither me nor my 11-year old daughter with whom we're learning Python can figure out where the problem is. We get the following error:_ \n> _ ================ RESTART: C:/Users/Enarpol/Desktop/brajan.py ================_ \n> _ Traceback (most recent call last):_ \n> _ File \"C:/Users/Enarpol/Desktop/brajan.py\", line 5, in <module>_ \n> _ class Piłka:_ \n> _ File \"C:/Users/Enarpol/Desktop/brajan.py\", line 20, in Piłka_ \n> _ if pozycja[1] <= 0:_ \n> _ NameError: name 'pozycja' is not defined_ \n> _And the code is exactly like in the book (some words are in Polish, but I assume it's not a problem for you to trace the error despite of it)_\n\nYour problem problem is caused by indentation and the idea of \"scope\" - I guess you're using the Polish language version of the book, so I'm not sure of the correct page number, but in the English language version of the book the section on _Variables and Scope_ (page 84) would be useful to re-read.\n\nIn short, here is the incorrect bit of your code:\n\n```python\n def rysuj(self):\n self.płótno.move(self.id, self.x, self.y)\n pozycja = self.płótno.coords(self.id)\n if pozycja[1] <= 0:\n self.y = 3\n```\n\nIf I re-indent this with visible spaces, to show how it should look, hopefully you can see what you need to fix in the rest of your code:\n\n```python\n def rysuj(self):\n self.płótno.move(self.id, self.x, self.y)\n pozycja = self.płótno.coords(self.id)\n ␣␣␣␣if pozycja[1] <= 0:\n ␣␣␣␣ self.y = 3\n```\n\nWhy does this make a difference? Because in the case of `rysuj` above, the variable `pozycja` is only visible within the function - or to be exact, within the block of code that makes up the function. And how do we create a block of code? Basically through indentation. Your `if` statement was at the same indentation level as `def rysuj(self)`, so it wasn't part of the function and that's why you're getting the error `name 'pozycja' is not defined`.\n\nHope that helps.", "content_html": "Marzena writes:
\n\n\nI'm writing to you because neither me nor my 11-year old daughter with whom we're learning Python can figure out where the problem is. We get the following error:
\n
\n ================ RESTART: C:/Users/Enarpol/Desktop/brajan.py ================
\n Traceback (most recent call last):
\n File \"C:/Users/Enarpol/Desktop/brajan.py\", line 5, in <module>
\n class Piłka:
\n File \"C:/Users/Enarpol/Desktop/brajan.py\", line 20, in Piłka
\n if pozycja[1] <= 0:
\n NameError: name 'pozycja' is not defined
\nAnd the code is exactly like in the book (some words are in Polish, but I assume it's not a problem for you to trace the error despite of it)
Your problem problem is caused by indentation and the idea of \"scope\" - I guess you're using the Polish language version of the book, so I'm not sure of the correct page number, but in the English language version of the book the section on Variables and Scope (page 84) would be useful to re-read.
\nIn short, here is the incorrect bit of your code:
\n def rysuj(self):\n self.płótno.move(self.id, self.x, self.y)\n pozycja = self.płótno.coords(self.id)\n if pozycja[1] <= 0:\n self.y = 3If I re-indent this with visible spaces, to show how it should look, hopefully you can see what you need to fix in the rest of your code:
\n def rysuj(self):\n self.płótno.move(self.id, self.x, self.y)\n pozycja = self.płótno.coords(self.id)\n ␣␣␣␣if pozycja[1] <= 0:\n ␣␣␣␣ self.y = 3Why does this make a difference? Because in the case of rysuj above, the variable pozycja is only visible within the function - or to be exact, within the block of code that makes up the function. And how do we create a block of code? Basically through indentation. Your if statement was at the same indentation level as def rysuj(self), so it wasn't part of the function and that's why you're getting the error name 'pozycja' is not defined.
Hope that helps.
", "date_published": "2019-05-08T18:49:57+01:00" }, { "id": "https://jasonrbriggs.com/journal/2019/03/16/traditional-chinese.html", "title": "Traditional Chinese", "url": "https://jasonrbriggs.com/journal/2019/03/16/traditional-chinese.html", "content_text": "你 好!\n\n[](/journal/2019/03/16/traditional-chinese-cover.webp)\n\nAvailable from [Wu Nan Books](https://www.wunanbooks.com.tw/product.php?isbn=9789577631688).", "content_html": "你 好!
\n
Available from Wu Nan Books.
", "date_published": "2019-03-16T10:42:51+00:00" }, { "id": "https://jasonrbriggs.com/journal/2019/01/31/stickman-moves.html", "title": "Stickman Moves", "url": "https://jasonrbriggs.com/journal/2019/01/31/stickman-moves.html", "content_text": "Alex Z writes (edited):\n\n> _I'm playing with the last chapter game, cf. the stickmangame7.py file. I'm a little confused about how the key presses are expected_\n> _to cause the character \\[to\\] move._ \n>\n> _If the player hits the right or left key, the character starts moving but keeps moving and doesn't stop unless \\[colliding\\] against a_\n> _wall or a platform. Even jumping on a platform doesn't cause the stick figure to stop. This makes hard to climb to the top parts of the area._\n> _Is it the expected behavior of the game ?_\n>\n> _I am not the first to experience this problem, see the folowing message on stackoverflow:_\n> _[How to move character only when key is pressed down Python](https://stackoverflow.com/questions/45301059/how-to-move-character-only-when-key-is-pressed-down-python)_\n\nYes, that is the expected behaviour of the game. The point is to make it more difficult to reach the top platform, so once the character starts running he doesn't stop, unless he collides with something. However, if you do want to change it so that the character only moves when the key is held down, there's a few fairly minor modifications you can make (which are discussed in that stack overflow article):\n\ni. Add a new function to stop the character moving, by changing the value of the `x` variable to 0. So in the StickFigureSprite sprite class we add this new function:\n```python\nclass StickFigureSprite(Sprite):\n ...\n ...\n ...\n def stop_moving(self, evt):\n self.x = 0\n```\nii. Now we need a way to call the new function. So we add two new key bindings to the `__init__` function of the same class, and set the starting value of the `x` variable to 0 (it's currently set to -2 so that the stick figure starts running as soon as the game starts):\n```python\nclass StickFigureSprite(Sprite):\n def __init__(self, game):\n ...\n ...\n self.x = 0\n ...\n ...\n game.canvas.bind_all('Alex Z writes (edited):
\n\n\nI'm playing with the last chapter game, cf. the stickmangame7.py file. I'm a little confused about how the key presses are expected\nto cause the character [to] move.
\nIf the player hits the right or left key, the character starts moving but keeps moving and doesn't stop unless [colliding] against a\nwall or a platform. Even jumping on a platform doesn't cause the stick figure to stop. This makes hard to climb to the top parts of the area.\nIs it the expected behavior of the game ?
\nI am not the first to experience this problem, see the folowing message on stackoverflow:\nHow to move character only when key is pressed down Python
\n
Yes, that is the expected behaviour of the game. The point is to make it more difficult to reach the top platform, so once the character starts running he doesn't stop, unless he collides with something. However, if you do want to change it so that the character only moves when the key is held down, there's a few fairly minor modifications you can make (which are discussed in that stack overflow article):
\ni. Add a new function to stop the character moving, by changing the value of the x variable to 0. So in the StickFigureSprite sprite class we add this new function:\n
class StickFigureSprite(Sprite):\n ...\n ...\n ...\n def stop_moving(self, evt):\n self.x = 0__init__ function of the same class, and set the starting value of the x variable to 0 (it's currently set to -2 so that the stick figure starts running as soon as the game starts):\nclass StickFigureSprite(Sprite):\n def __init__(self, game):\n ...\n ...\n self.x = 0\n ...\n ...\n game.canvas.bind_all('<KeyRelease-Left>', self.stop_moving)\n game.canvas.bind_all('<KeyRelease-Right>', self.stop_moving)So with these changes the game starts and the stick man won't move. When you hold the left or right key down, the x variable is set to -2 or 2 respectively which starts \"him\" moving. When you release the key, it sets the value back to 0, which stops him moving again.
You might notice one slight problem when running the game after this change - the stickman starts quickly and then slows down. This is caused by the keyboard repeating which then impacts the performance of the mainloop function in the Game class. This is an unfortunate side effect of the way the code for the game is written (the stickman code is not the standard way to handle animation with tkinter -- however it was written this way to hopefully make animation concepts, in programming, slightly easier for a child to understand).
Jobakhan writes (edited):
\n\n\nUsing this code
\n
\nimport sys
\ndef moon_weight():
\n print('Please enter your current Earth weight')
\n weight = float(sys.stdin.readline())
\n print('Please enter the amount your weight might increase each year')
\n increase = float(sys.stdin.readline())
\n print('Please enter the number of years')
\n years = int(sys.stdin.readline())
\n years = years + 1
\n for year in range(1, years):
\n weight = weight + increase
\n moon_weight = weight * 0.165
\n print('Year %s is %s' % (years , moon_weight))then it gives me this:
\n
\n
\nWhy is this happening?
It looks like you're using iPython/Jupyter Notebook to run the examples in the book. Python for Kids wasn't specifically written to work with iPython (nor was the code actually tested with that app), which is why you're having issues. Having said that, I think many of the examples will work, but some, like the code you sent, will need modification.
\nIn the case of the moon_weight function, it's using sys.stdin.readline() (that's the sys module, \"standard input\" object, readline function) to read input from the user running the program. There are a couple of ways to read command line input in Python - and in the case of Jupyter it looks like stdin doesn't behave the same way as the Python shell. I found the following in the Jupyter client documentation:
\n\nThis pattern of requesting user input is quite different from how stdin works at a lower level. \nThe Jupyter protocol does not support everything code running in a terminal can do with stdin...
\n
So what's actually happening when you run that code? The function sys.stdin.readline() returns straight away with an empty string (''), and Python then throws an error when trying to convert that empty string to a floating point number. If you replace sys.stdin.readline() in the above code with input(), the program should then work in jupyter:
weight = float(input())\n...\nincrease = float(input())\n...\nyears = int(input())Lucia C writes:
\n\n\nI am currently reading your book but do not have access to a computer. I do however have my Ipad pro.
\nThere is an app available called Pythonista 3, are you familiar with this app and would you recomend it to follow your book?
\n
Unfortunately, Pythonista has it's own custom UI library, so I don't believe it supports turtle or tkinter -- the latter chapters of the book rely heavily on tkinter for graphics in the games. Without this you're going to struggle completing all the examples.
\nIf you only have an iPad, a cheap option might be to purchase a Raspberry Pi (at time of writing a Pi starter kit is UK£51.99/US$79.99) and use that for your programming activities. While you'll initially need a monitor as well, if you want to stick with the iPad, it looks like it is possible to connect from the iPad to the Pi (so your iPad effectively becomes the monitor) using VNC -- more info can be found here in this instructables article.
\nHope that helps.
", "date_published": "2019-01-26T10:03:56+00:00" }, { "id": "https://jasonrbriggs.com/journal/2018/09/29/trouble-with-gimp.html", "title": "Trouble with GIMP", "url": "https://jasonrbriggs.com/journal/2018/09/29/trouble-with-gimp.html", "content_text": "Tom writes (excerpted):\n\n> _I'm learning Python from your book and I'm finding it a great resource. However, I'm at the point where I'm creating the StickMan game_\n> _and I'm having issues. I'm using an iMac running MacOS Sierra 10.12.6 The version of GIMP that I downloaded is 2.8.18._\n> _Specifically, I'm at Part III, chapter 15, \"Creating the Game Elements-Preparing a Transparent Image\". Steps 1 through 3 go well,_ \n> _but when I go to \"Select -> All\", there is no \"All\" in the \"Select\" menu. I am also having issues with the paintbrush as a dot._\n> _It shows up as a large square and will blot out most of the 27x30 image that I'm trying to paint. Gimp seems to be prompting me_\n> _to add other layers, but I'm not clear as to how that will affect the image I'm trying to create._\n\nI'm only using a slightly later version of GIMP than you at the moment (2.10), and I don't see any issues - though I'm not running Sierra, I doubt that makes a significant difference. For example, in terms of the Select menu, I can see All at the top:\n\n[](/journal/2018/09/29/select-all.webp)\n\nIn terms of your problem with the brush, if you look at the brushes palette, the single pixel (1x1 square) is almost at the bottom:\n\n[](/journal/2018/09/29/brush.webp)\n\n(Not entirely sure what you're seeing, but hopefully those screenshots help?)\n\nFinally, regarding layers in Gimp, those aren't necessarily an issue. When you export the image (as a gif or png or anything else) it should collapse the layers into one -- and even if you find them annoying, you can click on the top layer in the layers dialog, select the Layers menu, and then click Merge Down to collapse into the next layer in the list.\n\n\n", "content_html": "Tom writes (excerpted):
\n\n\nI'm learning Python from your book and I'm finding it a great resource. However, I'm at the point where I'm creating the StickMan game\nand I'm having issues. I'm using an iMac running MacOS Sierra 10.12.6 The version of GIMP that I downloaded is 2.8.18.\nSpecifically, I'm at Part III, chapter 15, \"Creating the Game Elements-Preparing a Transparent Image\". Steps 1 through 3 go well, \nbut when I go to \"Select -> All\", there is no \"All\" in the \"Select\" menu. I am also having issues with the paintbrush as a dot.\nIt shows up as a large square and will blot out most of the 27x30 image that I'm trying to paint. Gimp seems to be prompting me\nto add other layers, but I'm not clear as to how that will affect the image I'm trying to create.
\n
I'm only using a slightly later version of GIMP than you at the moment (2.10), and I don't see any issues - though I'm not running Sierra, I doubt that makes a significant difference. For example, in terms of the Select menu, I can see All at the top:
\n
In terms of your problem with the brush, if you look at the brushes palette, the single pixel (1x1 square) is almost at the bottom:
\n
(Not entirely sure what you're seeing, but hopefully those screenshots help?)
\nFinally, regarding layers in Gimp, those aren't necessarily an issue. When you export the image (as a gif or png or anything else) it should collapse the layers into one -- and even if you find them annoying, you can click on the top layer in the layers dialog, select the Layers menu, and then click Merge Down to collapse into the next layer in the list.
", "date_published": "2018-09-29T16:18:29+01:00" } ] }